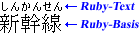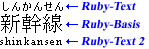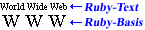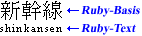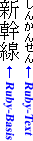Ruby-Annotation (W3C)
- Originalversion:
- https://www.w3.org/TR/ruby/
- Übersetzer:
- Jens Oliver Meiert, meiert.com
- Datum der Übersetzung:
- 19. Oktober 2003 (↻ 7. Februar 2007)
Bei diesem Dokument handelt es sich um die deutsche Übersetzung eines W3C-Textes. Dieser Text ist urheberrechtlich geschützt; bitte beachten Sie die Hinweise des Originaldokuments sowie die Anmerkungen der W3C-Dokumentlizenz. Die Übersetzung hat keine durch das W3C legitimierte, normative Wirkung. Das einzige maßgebliche Dokument ist das englische Original.
Bitte senden Sie Fehler und Korrekturen zur deutschen Fassung an den Übersetzer. Kommentare des Übersetzers, die als solche gekennzeichnet sind, unterliegen dem Urheberrecht des Übersetzers. Sie sind kein Bestandteil des Ursprungsdokuments. – Interessierte finden in JGloss eine Anwendung, die dem Hinzufügen von Lesungs- und Übersetzungs-Annotationen zu Wörtern in einem japanischen Textdokument dient und diese Spezifikation berücksichtigt.

Ruby-Annotation
W3C-Empfehlung vom 31. Mai 2001
- Diese Version:
- https://www.w3.org/TR/2001/REC-ruby-20010531
(ZIP)
- Aktuelle Version:
- https://www.w3.org/TR/ruby
- Vorherige Version:
- https://www.w3.org/TR/2001/PR-ruby-20010406
- Herausgeber:
- Marcin Sawicki (bis zum 10. Oktober 1999)
- Michel Suignard, Microsoft
- Masayasu Ishikawa (石川 雅康), W3C
- Martin Dürst, W3C
- Tex Texin, Progress Software Corp.
- (Bitte beachten Sie die Danksagung, um mehr über weitere Mitwirkende zu erfahren)
Copyright © 1998–2001 W3C® (MIT, INRIA, Keio), alle Rechte vorbehalten. Es gelten die Haftungs-, Marken-, Dokumentverwendungs- und Lizenzierungsbestimmungen des W3C.
Kurzfassung
»Ruby« repräsentiert kurze Texte entlang einer Textbasis, die hauptsächlich in ostasiatischen Dokumenten zu finden sind, wenn eine besondere Betonung oder eine kurze Erläuterung dargestellt werden soll. Die vorliegende Spezifikation definiert das Markup für Ruby als XHTML-Modul [XHTMLMOD].
Status dieses Dokuments
Dieser Abschnitt beschreibt den Status dieses Dokuments zur Zeit seiner Veröffentlichung. Andere Dokumente können an seine Stelle treten. Der letzte Stand dieser Reihe von Dokumenten wird vom W3C betreut.
Dieses Dokument wurde von Mitgliedern des W3C und anderen interessierten Parteien geprüft und vom Direktor als W3C-Empfehlung bestätigt. Es ist ein stabiles Dokument und kann als Referenzmaterial verwendet oder als normative Referenz von einem anderen Dokument zitiert werden. Die Rolle des W3C bei der Erstellung dieser Empfehlung ist, die Spezifikation bekannt zu machen und ihre breite Anwendung zu fördern. Dies erhöht die Funktionsfähigkeit und Interoperabilität des Internets.
Das vorliegende Dokument wurde als Teil der vom W3C initiierten Internationalisierungsaktivität von der Arbeitsgruppe Internationalisierung (I18N-WG, nur für Mitglieder) mit Unterstützung durch die Interessengruppe Internationalisierung (I18N-IG) geschrieben. Kommentare sollten an die öffentlich archivierte Mailingliste www-i18n-comments@w3.org gesendet werden. Kommentare und Anmerkungen auf anderen Sprachen als Englisch, insbesondere auf Japanisch, sind ebenso willkommen. Eine öffentliche Diskussion zu diesem Dokument wird auf der www-international@w3.org-Mailingliste geführt (siehe Archiv).
Aufgrund der Charakteristik des behandelten Themas und um realistischere Beispiele heranzuziehen behilft sich dieses Dokument einer großen Menge an Zeichen bzw. Zeichensätzen. Eventuell ist nicht jeder User-Agent (zum Beispiel Webbrowser) in der Lage, alle Zeichen korrekt darzustellen – je nach User-Agent kann es deshalb sinnvoll sein, die Konfiguration anzupassen. Es wurden für dieses Dokument jedoch auch entsprechende Anstrengungen unternommen, um es für verschiedenste Zeichenkodierungen und somit eine große Spanne User-Agents und Konfigurationen anbieten zu können.
Weitere auf dieses Dokument bezogene Informationen können auf der öffentlichen Ruby-Seite gefunden werden, welche neben weiteren Übersetzungen dieser Spezifikation auch mögliche Errata beinhaltet. Eine Liste aktueller W3C-Empfehlungen und weiterer technischer Dokumente finden Sie unter https://www.w3.org/TR.
Zu dieser Spezifikation gibt es bislang keine patentbezogenen Erklärungen seitens der Arbeitsgruppe Internationalisierung.
Inhaltsverzeichnis
1. Einleitung
Dieser Abschnitt ist informell.
Dieses Dokument stellt einen Überblick über die Ruby-Annotation dar, definiert das entsprechende Markup und bietet eine Reihe von Beispielen. Nichtsdestotrotz werden in diesem Dokument keinerlei Mechanismen für die Präsentation (Visualisierung) oder die Gestaltung der Ruby-Annotation spezifiziert, da dies Aufgabe der verwendeten Stylesheet-Sprache ist.
Das Dokument ist wie folgt aufgebaut:
Abschnitt 1.1 bietet eine Übersicht über die Ruby-Annotation.
Abschnitt 1.2 bietet eine Übersicht über das Markup von Ruby.
Abschnitt 2 liefert die normative Definition von Ruby-Markup.
Abschnitt 3 erörtert das gewöhnliche Rendern und Gestalten von Ruby-Text.
Abschnitt 4 definiert die Konformitätskriterien.
1.1 Was ist Ruby?
Ruby ist ein Begriff für einen Textbereich, der mit einem anderen Text, der sogenannten Textbasis, verbunden ist. Ruby-Text wird gebraucht, um eine kurze Erläuterung zum verknüpften Basistext zu liefern, meistens jedoch, um gewissermaßen als Ausspracheanleitung die entsprechende Lesart zu definieren. Ruby-Annotationen werden in Japan häufig als Bestandteil vieler Arten von Publikationen (wie Büchern und Zeitschriften) verwendet, aber sie finden ihre Anwendung auch in China, wo sie insbesondere in Schulbüchern herangezogen werden.
Ruby-Text wird gewöhnlich mit kleinerer Schriftart entlang des Basistextes (auch: Textbasis) dargestellt. Der Name »Ruby« stammt ursprünglich vom Namen der 5,5-Punkt-Schriftgröße im britischen Buchdruck, welche lediglich etwa die Hälfte der gewöhnlich verwendeten 10-Punkt-Größe für normalen Text beträgt. Abbildung 1.1 zeigt ein Beispiel anhand von drei Ideogrammen (Kanji) als Textbasis sowie sechs Hiragana, die die Lesart bestimmen (hier: Shinkansen, ein japanischer Hochgeschwindigkeitszug).
Die ostasiatische Typographie hat eine Vielzahl von Besonderheiten hervorgebracht, die nicht in der westlichen erscheinen. Die meisten davon können über Stylesheet-Sprachen wie CSS oder XSL ausreichend angegangen werden – trotzdem ist es notwendig, dass zusätzliches Markup die Verbindung zwischen Basis- und Ruby-Text herstellt.
Diese Spezifikation definiert ein solches Markup, das zusammen mit XHTML verwendet werden und somit im Web ohne besondere Workarounds oder Graphiken zum Einsatz kommen kann. Obwohl diese Spezifikation Beispiele zum gegenwärtigen Rendern liefert, um es den meisten Lesern leichter zu machen, das Markup zu verstehen, sind diese Beispiele nur informeller Natur. Dieses Dokument spezifiziert keinerlei Mechanismen für die Präsentation oder die Formatierung, da dies wie oben beschrieben Aufgabe der gebrauchten Stylesheet-Sprache ist.
Manchmal kann es vorkommen, dass mehr als ein Ruby-Text mit derselben Textbasis assoziiert wird. Ein typisches Beispiel ist, sowohl Bedeutung als auch Aussprache bzw. Lesart für eine Textbasis anzeigen zu wollen. In solchen Fällen können Ruby-Texte auf beiden Seiten der Textbasis erscheinen: Ruby-Text vor der Basis wird oft dazu verwendet, die Lesart darzustellen, während er hinter der Textbasis die Bedeutung aufzeigen soll. Abbildung 1.2 veranschaulicht dies anhand von zwei Ruby-Texten, die sowohl die Lesart via Hiragana als auch die Bedeutung in lateinischen Schriftzeichen festlegen.
Zusätzlich kann jeder Ruby-Text auch mit unterschiedlichen Teilen der Textbasis verknüpft werden, wie es das folgende Beispiel veranschaulicht:
In diesem Beispiel ist der Basistext das Datum »31 10 2002«. Ein Ruby-Text entspricht dem Begriff »Verfallsdatum« und wird dabei auf die komplette Textbasis angewandt, während hingegen der andere Ruby-Text in drei Teile separiert ist: »Tag«, »Monat« und »Jahr«. Jeder Teil hiervon ist mit einem unterschiedlichen Part des Basistextes verknüpft, denn »Tag« wird mit »31« assoziiert, »Monat« mit »10«, und »Jahr« mit »2002«.
1.2 Überblick über Ruby-Markup
Das in dieser Spezifikation definierte Markup wurde entworfen, um alle oben genannten Fälle abzudecken, im einzelnen also Markup für ein oder zwei Ruby-Texte, die zur selben Basis stehen, sowie Markup für Verknüpfungen von Untereinheiten von Ruby-Text mit einzelnen Bestandteilen der Textbasis.
Es gibt zwei Varianten des Ruby-Markups, die als einfaches Ruby-Markup und komplexes Ruby-Markup bezeichnet werden. Einfaches Ruby-Markup verbindet einen einzelnen Ruby-Text mit einem Basistext und bietet zusätzlich als Fallback noch einen Mechanismus, der es Browsern, die Ruby-Markup nicht parsen können, erlaubt, den Ruby-Text darzustellen. Komplexes Ruby-Markup kann zum einen zwei Ruby-Texte mit einer Basis assoziieren, zum anderen erlaubt es aber auch eine feinkörnige Verknüpfung von einzelnen Komponenten eines Ruby-Textes mit Teilen der Textbasis. Das komplexe Ruby-Markup inkludiert jedoch keinen Fallback-Mechanismus für Browser, die das Ruby-Markup nicht verstehen.
Dieser Abschnitt bietet einen Überblick über das in dieser Spezifikation definierte Markup für Ruby. Die vollständig formale Definition befindet sich in Abschnitt 2.
1.2.1 Einfaches Ruby-Markup
Im einfachsten Fall definiert das Ruby-Markup ein ruby-Element, welches ein rb- für den Basistext und ein rt-Element für den Ruby-Text beinhaltet. Folglich erstellt das ruby-Element eine Verknüpfung von Textbasis und Ruby-Text, was in den meisten Fällen ausreichend sein sollte. Hier ein Beispiel für einfaches Ruby-Markup:
Dies könnte wie folgt gerendert werden:
Anmerkung: Das umschließende ruby-Element sollte mit der Bedeutung interpretiert werden, dass sein Inhalt den mit Basistext assoziierten Ruby-Text darstellt. Es sollte nicht so verstanden werden, dass der komplette eingeschlossene Teil (inklusive dem Basistext) Ruby ist; vielmehr wurde der Name des einkapselnden Elements so gewählt, dass er klar und in kompakter Form die Funktion des Markup-Konstrukts identifiziert, während die anderen Elementen so benannt wurden, dass ihre Namen kurz bleiben.
1.2.2 Einfaches Ruby-Markup mit Parenthesen
Einige User-Agents verstehen Ruby-Markup unter Umständen nicht bzw. sind nicht in der Lage, Ruby-Text korrekt darzustellen. In beiden Situationen mag es vorzuziehen sein, dass der Ruby-Text gerendert wird, damit die entsprechenden Informationen nicht verloren gehen. Ein durchaus annehmbarer Fallback besteht darin, den Ruby-Text unmittelbar hinter dem Basistext zu platzieren und ihn mit einer Parenthese (Klammer) zu umschließen. Diese Parenthese verringert die Wahrscheinlichkeit, dass Ruby-Text mit anderem Text verwechselt wird. (Es sollte Erwähnung finden, dass in Parenthesen dargestellter Text in der japanischen Typographie niemals »Ruby« genannt wird.)
Um Kompatibilität zu älteren User-Agents, die das Ruby-Markup nicht verstehen und einfach den Inhalt der Elemente rendern, die sie nicht kennen, zu ermöglichen, können rp-Elemente zum einfachem Ruby-Markup hinzugefügt werden, um Ruby-Text hervorzuheben.
Der Elementname rp steht für »Ruby-Parenthese«. Die rp-Elemente und umfassten Parenthesen (bzw. anderen Zeichen) werden lediglich als Fallback-Mechanismus angeboten. User-Agents, die unbekannte Elemente ignorieren, aber deren Inhalte darstellen, werden den Inhalt jedes rp-Elements ausgeben. Folglich kann das rp-Element dazu gebraucht werden, um sowohl Anfang als auch Ende des Ruby-Textes zu kennzeichnen.
User-Agents, die Ruby-Markup verstehen, werden das rp-Element erkennen und somit seinen Inhalt absichtlich nicht darstellen; statt dessen werden sie das einfache Ruby-Markup auf sachgemäßere Weise rendern.
Das folgende Beispiel illustriert den Gebrauch des rp-Elements:
User-Agents, die entweder
- kein Ruby-Markup verstehen, aber den Inhalt ihnen unbekannter Elemente rendern, oder die
- keinen Ruby-Text entlang der Textbasis rendern können,
werden obiges Markup wie folgt darstellen:
User-Agents, die mit Ruby-Markup umgehen können und fortgeschrittenere Präsentationsarten für Ruby-Text beinhalten, werden die Parenthesen nicht rendern. Als Beispiel soll das Markup aus Abbildung 1.6 entsprechend visualisiert werden:
1.2.3 Komplexes Ruby-Markup
Komplexes Ruby-Markup wird verwendet, um mehr als einen Ruby-Text mit einem Basistext zu assoziieren, oder um Teile dieses Textes mit korrespondierenden Teilen des Basistextes zu verknüpfen.
Komplexes Ruby-Markup sieht vor, dass mehrere rb- und rt-Elemente eingebunden werden. Diese Spezifikation definiert spezielle Elemente als Container, um die Assoziation zwischen einzelnen Elementen deutlich zu machen. Der Ruby-Base-Container (rbc-Element) umschließt rb-Elemente, während es ein oder zwei Ruby-Text-Container (die rtc-Elemente) geben kann, die die entsprechenden rt-Elemente einschließen. Dies ermöglicht die Verknüpfung von zwei Ruby-Text-Containern mit demselben Basistext. Mit komplexem Ruby-Markup ist es auch möglich, Teile der Textbasis mit Teilen eines Ruby-Textes zu assoziieren, indem man eine Anzahl von rb-Elementen sowie die entsprechend selbe Menge rt-Elemente definiert. Des weiteren kann das rt-Element über das rbspan-Attribut anzeigen, dass ein einzelnes rt- mit mehreren rb-Elementen assoziiert wird und diese umspannt. Dies entspricht in etwa dem colspan-Attribut der th- und td-Elemente in Tabellen ([HTML4], Abschnitt 11.2.6).
Wo und wie jeder Teil komplexen Ruby-Markups gerendert wird, ist jeweils Aufgabe der verwendeten Stylesheet-Sprache; siehe Abschnitt 3 für weitere Informationen.
Das folgende Beispiel verdeutlicht alle zuvor aufgeführten Merkmale:
Im Beispiel umschließt der erste Ruby-Text-Container drei Komponenten, nämlich »Tag«, »Monat« und »Jahr«. Jeder dieser Bereiche wird mit einer entsprechenden Komponente im Basistext assoziiert (»31«, »10«, »2002«). Der zweite Ruby-Text-Container (»Verfallsdatum«) besteht aus einem einzigen Ruby-Text-Teil, der mit dem gesamten Basistext (»31 10 2002«) verknüpft wird. Dies kann wie in Abbildung 1.10 gerendert werden:
Das Beispiel zeigt, dass die Verknüpfung von Ruby- und Basistext so granular wie jeweils erforderlich sein kann. So kann zum Beispiel sinnvoll sein, Ruby-Text mit dem kompletten Basistext zu assoziieren, wenn
- eine detailliertere Beziehung nicht bekannt ist, oder wenn
- die Lesart oder Erläuterung nur auf die gesamte Einheit angewandt und nicht weiter aufgeteilt werden kann.
Es können weitere feinkörnige Assoziationen geschaffen werden, sofern die Beziehungen bzw. Verhältnisse zur Textbasis bekannt sind. So kann der Name einer Person in Vorname und Nachname zerlegt werden, auch kann beispielsweise eine Kanji-Zusammensetzung oder ein Satz in semantische Untereinheiten bzw. unterschiedliche Zeichen aufgeteilt werden. Egal welche Art von Granularität gewünscht wird, die Spanne des jeweiligen Ruby-Textes kann den korrespondierenden Teilen des Basistextes entsprechend gesetzt werden, so dass möglicherweise eine bessere Lesbarkeit und ein ausgeglicheneres Layout erzielt werden.
Das rp-Element kann im Fall komplexen Ruby-Markups nicht verwendet werden, wofür es zwei Gründe gibt: Zum einen dient das rp-Element lediglich als Fallback-Mechanismus, welcher im häufigeren Fall, nämlich der Verwendung von einfachem Ruby-Markup, als notwendiger angesehen wurde. Zum anderen ist es in Bezug auf die komplexeren Fälle schwierig, sich eine angemessene Fallback-Darstellung einfallen zu lassen, und das Kreieren von Markup für solche Fälle kann schwierig, wenn nicht gar unmöglich sein.
1.2.4 Zusammenfassung
Das ruby-Element dient als Container in den folgenden Fällen:
-
Eine Kombination aus
rb-, rt- und evtl. rp-Elementen (einfaches Ruby-Markup) als
- Verknüpfung eines einzigen Ruby-Textes mit einem Basistext und
- Fallback für den Fall, dass das Ruby-Markup nicht verstanden wird.
-
Eine Kombination eines einzelnen
rbc- und einem oder zwei rtc-Container-Elementen (komplexes Ruby-Markup) als
- Verknüpfung von zwei Ruby-Texten mit demselben Basistext und
- Definition feingranularer Verknüpfungen zwischen Teilen eines Ruby-Textes und Teilen der Textbasis.
2. Formelle Definition des Ruby-Markup
Dieser Abschnitt ist normativ.
Dieser Abschnitt beinhaltet die formelle Syntaxdefinition und die Spezifikation der Funktionalität des Ruby-Markups. Eine gewisse Vertrautheit mit dem Framework der XHTML-Modularisierung, im Besonderen der Modularization of XHTML-Spezifikation [XHTMLMOD], wird vorausgesetzt.
2.1 Abstrakte Definition des Ruby-Markups
Der folgende Teil entspricht der abstrakten Definition der Elemente des Ruby-Markups, die in Einklang mit dem Framework der XHTML-Modularisierung steht. Weitere Informationen über abstrakte XHTML-Module liegen in der Dokumentation von [XHTMLMOD] vor.
| Elemente
| Attribute
| Minimales Inhaltsmodell
|
| ruby
| Allgemein
| (rb, (rt | (rp, rt, rp)))
|
| rbc
| Allgemein
| rb+
|
| rtc
| Allgemein
| rt+
|
| rb
| Allgemein
| (PCDATA | Inline - ruby)*
|
| rt
| Allgemein, rbspan (CDATA)
| (PCDATA | Inline - ruby)*
|
| rp
| Allgemein
| PCDATA*
|
Das maximale Inhaltsmodell des ruby-Elements entspricht:
((rb, (rt | (rp, rt, rp))) | (rbc, rtc, rtc?))
Das minimale Inhaltsmodell des ruby-Elements entspricht einfachem Ruby-Markup. Der (rbc, rtc, rtc?)-Part des maximalen Inhaltsmodells des ruby-Elements ist hingegen ausschließlich komplexem Ruby-Markup zuzuordnen.
Auf eine Implementierung dieser abstrakten Definition als XHTML-DTD-Modul wird in Anhang A verwiesen. An einer XML-Schema-Implementierung [XMLSchema] wird gearbeitet, siehe auch [ModSchema].
2.2 Das ruby-Element
Das ruby-Element ist ein Inline- bzw. Text-Level-Element, welches als Gesamtcontainer dient. Es beinhaltet entweder rb-, rt- und optional rp-Elemente (einfaches Ruby-Markup), oder rbc- und rtc-Elemente (komplexes Ruby-Markup).
Im Fall einfachen Ruby-Markups beinhaltet das ruby-Element entweder ein rb-, gefolgt von einem rt-Element, oder eine Sequenz eines rb-, rp-, rt- und eines weiteren rp-Elements. Der Inhalt des rt-Elements wird als Ruby-Text angesehen und mit dem Inhalt des rb-Elements (Basistext) assoziiert. Der Inhalt des rp-Elements wird, sofern vorhanden, ignoriert.
Liegt komplexes Ruby-Markup vor, umfasst das ruby-Element ein rbc-, gefolgt von einem oder zwei rtc-Elementen. Der Inhalt der Subelemente jedes rtc-Elements wird als Ruby-Text angenommen und mit dem Inhalt der Subelemente des rbc-Elements assoziiert, welches die Textbasis darstellt.
Das Ruby-Element besitzt lediglich allgemeine Attribute. Beispiele für allgemeine Attribute sind id, class oder xml:lang. Sie hängen von der jeweiligen Markupsprache ab, in deren Zusammenhang Ruby-Markup verwendet wird – im Fall von [XHTML 1.1] sind diese unter XHTML Modularization, Abschnitt 5.1 [XHTMLMOD] zu finden.
2.3 Das rbc-Element
Das rbc-Element (Ruby-Base-Container) dient im Fall komplexen Ruby-Markups als Container für rb-Elemente. Innerhalb eines ruby-Elements darf nur ein rbc-Element verwendet werden.
Das rbc-Element besitzt lediglich allgemeine Attribute.
2.4 Das rtc-Element
Das rtc-Element (Ruby-Text-Container) dient im Fall komplexen Ruby-Markups als Container für rt-Elemente. Innerhalb eines ruby-Elements dürfen ein oder zwei rtc-Elemente verwendet werden, um als Ruby-Texte mit einem Basistext assoziiert zu werden. Dieser Basistext wird durch ein rbc-Element repräsentiert. Es DÜRFEN NICHT mehr als zwei rtc-Elemente innerhalb eines ruby-Elements verwendet werden.
Das rtc-Element besitzt lediglich allgemeine Attribute.
2.5 Das rb-Element
Das rb-Element hebt den Basistext hervor. Innerhalb von einfachem Ruby-Markup darf nur ein rb-Element erscheinen; bei komplexem Ruby-Markup können mehrere rb- innerhalb eines rbc-Elements verwendet werden. Jedes rb-Element wird mit dem korrespondierenden rt-Element assoziiert, was eine feinkörnige Kontrolle der Ruby-Visualisierung gestattet.
Das rb-Element kann Inline-Elemente oder Zeichen (Character Data) als Inhalt haben. Das ruby-Element darf nicht Nachkomme dieses Elements sein.
Das rb-Element besitzt lediglich allgemeine Attribute.
2.6 Das rt-Element
Das rt-Element ist das Markup für Ruby-Text. Bei einfachem Ruby-Markup darf lediglich ein rt-Element verwendet werden; bei komplexem Ruby-Markup dürfen mehrere rt-Elemente innerhalb eines rtc-Elements gebraucht werden, wobei jedes rt-Element den Ruby-Text für den relevanten Basistext darstellt, welcher durch die entsprechenden rb-Elemente repräsentiert wird.
Das rt-Element kann Inline-Elemente oder Zeichen (Character Data) als Inhalt haben. Das ruby-Element darf nicht Nachkomme dieses Elements sein.
Das rt-Element besitzt die allgemeinen sowie das rbspan-Attribut. Im Fall komplexen Ruby-Markups erlaubt das rbspan-Attribut einem rt-Element, mehrere rb-Elemente zu umspannen. Der entsprechende Wert sollte ein Integer-Wert sein, der größer als Null (»0«) ist; Default-Wert dieses Attributs ist Eins (»1«). Das rbspan-Attribut sollte nicht in einfachem Ruby-Markup verwendet werden, und User-Agents sollten es ignorieren, wenn es innerhalb von einfachem Ruby-Markup verwendet wird.
2.7 Das rp-Element
Das rp-Element kann innerhalb von einfachem Ruby-Markup gebraucht werden, um Zeichen zu spezifizieren, die Anfang und Ende von Ruby-Text kennzeichnen sollen, wenn User-Agents keinen anderen Weg finden, Ruby-Text unverwechselbar vom Basistext darzustellen. Parenthesen (oder ähnliche Zeichen) können somit einen akzeptablen Fallback darstellen: In diesem Fall wird Ruby-Text so verändert, dass er inline gerendert und von den Fallback-Parenthesen umschlossen wird. Dies entspricht dem am wenigsten unpassenden Rendern unter der Voraussetzung, dass nur Inline-Rendern möglich ist. Das rp-Element kann nicht innerhalb von komplexem Ruby-Markup verwendet werden.
Das rp-Element besitzt lediglich allgemeine Attribute.
Parenthesen als Fallback-Mechanismus zu verwenden mag zu Konfusion zwischen Textabschnitten, die Ruby-Text darstellen sollen, und anderen Textbereichen, die von Parenthesen umschlossen sind, führen. Der Autor des Dokuments oder Stylesheets sollte sich dieser Gefahr bewusst sein, und es wird deshalb geraten, unzweideutige Begrenzungszeichen für diesen Fallback zu wählen.
3. Hinweise zum Rendern und Darstellen
Dieser Abschnitt ist informell.
Dieser Abschnitt behandelt verschiedene Aspekte bezüglich Rendern und Gestalten von Ruby-Markup, wie es in diesem Dokument definiert wird. Dieses Dokument spezifiziert jedoch keine Mechanismen für die Präsentation oder das Styling – dies wird der entsprechenden Stylesheet-Sprache überlassen. Formateigenschaften, die Ruby in Form von Styles zugewiesen werden können, werden für CSS und XSL entwickelt, siehe zum Beispiel CSS3 Module: Ruby [CSS3-RUBY] (in Bearbeitung).
Details zur Formatierung von Ruby im Zusammenhang zum japanischen Druck können unter JIS-X-4051 [JIS4051] gefunden werden.
3.1 Ruby im Web vs. traditionelle typographische Verwendung
Der Begriff »Ruby« wird im Japanischen nur für Text gebraucht, der entlang eines Basistextes gerendert wird. Überlegungen zu solchen Fällen werden in Abschnitt 3.2 (Schriftgröße), Abschnitt 3.3 (Positionierung) und Abschnitt 3.4 (Darstellung von Ruby-Markup) angestellt. Diese Art der Präsentation sollte möglichst überall angewandt werden. Die Einführung von Ruby im Internet könnte jedoch zu besonderen Phänomenen und Problemen führen, die es auf dem Gebiet der traditionellen Typographie so nicht gibt. So kann strukturelles Markup für Ruby, wie es in dieser Spezifikation definiert wird, nicht garantieren, dass Ruby-Text auch immer entlang des Basistextes gerendert wird. Es gibt außerdem eine große Bandbreite an vorhandenen und zukünftigen Ausgabegeräten für Dokumente, deren Markup aus XHTML besteht, was zu folgenden Szenarien und Gründen für unterschiedliches Rendern führen kann:
- Auf non-visuellen User-Agents wie Sprach-Browsern und Braille-User-Agents ist nur sequentielles Rendern möglich; siehe Abschnitt 3.5 für weitere Überlegungen zur non-visuellen Darstellung.
- Bei Anzeigegeräten mit niedriger Auflösung mag das Darstellen von Ruby-Text in der gewöhnlichen Größe nicht realisierbar sein; siehe auch Abschnitt 3.6.
- Zu Bildungszwecken könnte es in bestimmten Fällen interessant sein, den Ruby-Text nicht anzuzeigen und nur als Popup verfügbar zu machen. Dies ist unmöglich auf Papier darzustellen, aber leicht durchführbar auf einem entsprechenden Anzeigegerät.
3.2 Schriftgröße von Ruby-Text
Im gewöhnlichen Gebrauch wird Ruby-Text mit etwa der halben Schriftgröße von der des Basistextes dargestellt. Der Name »Ruby« entspringt ursprünglich dem Namen der 5,5-Punkt-Schriftgröße im britischen Buchdruck, welche lediglich etwa die Hälfte der gewöhnlich verwendeten 10-Punkt-Größe für normalen Text beträgt.
3.3 Positionierung von Ruby-Text
Es gibt diverse Positionen, an denen Ruby-Text in Relation zu seinem Basistext erscheinen kann. Da ostasiatischer Text sowohl vertikal als auch horizontal gerendert werden kann, werden die Begriffe »vor« und »nach« hier eher gebraucht als »über« und »unter« bzw. »rechts« und »links«. Die Begriffe »vor« und »nach« sollten verstanden werden als »vor«/»nach« der Zeile, die den Basistext enthält. Der Zusammenhang wird in der folgenden Tabelle verdeutlicht:
| Terminologie
| Horizontales Layout
(von links nach rechts, oben nach unten)
| Vertikales Layout
(von oben nach unten, rechts nach links)
|
| vor
| über
| rechts
|
| nach
| unter
| links
|
Ruby-Texte werden meistens vor dem Basistext platziert (siehe Abbildung 1.1 und Abbildung 3.2). Manchmal kann Ruby-Text jedoch auch nach (unter) dem Basistext erscheinen, besonders bei zu Bildungszwecken horizontal ausgerichteten Dokumenten, siehe Abbildung 3.1. Auch im Chinesischen ist es eher so, dass Ruby-Text (Pinyin) nach dem Basistext folgt, ebenso in vertikalem Layout, wie es Abbildung 3.3 illustriert. In all diesen Fällen entspricht die Schreibrichtung des Ruby-Textes der des Basistextes, ergo ist sie vertikal, wenn der Basistext vertikal verläuft, und horizontal, wenn dieser horizontal verläuft.
In traditionellen chinesischen Texten kann Bopomofo-Ruby-Text sogar bei horizontaler Ausrichtung rechts entlang der Textbasis verlaufen.
Beachten Sie, dass Bopomofo-Betonungszeichen (in obigem Beispiel in rot gekennzeichnet) sich in einer separaten Spalte zu befinden scheinen (rechts entlang des Bopomofo-Ruby-Textes) und dadurch wie »Ruby in Ruby« aussehen mögen. Letztlich wurden diese Zeichen einfach als Teil des Ruby-Textes kodiert, wobei Details zu dieser Kodierung nicht in diesem Dokument erörtert werden.
3.4 Darstellung von Ruby-Markup
Diese Spezifikation schreibt nicht vor, wie Ruby-Markup dargestellt werden soll. Im Allgemeinen werden Stylesheets dafür verwendet, um das Verhalten des Markups exakt zu determinieren.
Anmerkung: Obwohl das Rendern des Ruby-Textes von Stylesheets kontrolliert werden sollte, wird empfohlen, dass visuelle User-Agents den Ruby-Text vor den Basistext platzieren, sofern nur ein Ruby-Text verwendet wird und keine Style-Informationen von Autor oder Benutzer geliefert werden. Dies sollte ebenfalls für einfaches Ruby-Markup gelten. Wenn zwei Ruby-Texte vorliegen, sollte der erste Text vor und der zweite nach dem Basistext angeordnet werden. Ein beispielhaftes Standard-Stylesheet, welches diese Formatierung beschreibt, wird von [CSS3-RUBY] oder seinem Nachfolgedokument geliefert werden.
Für non-visuelles Rendern wird bei Fehlen von Stylesheet-Informationen empfohlen, dass sowohl Basistext als auch Ruby-Text(e) unter besonderer Hervorhebung (zum Beispiel durch unterschiedliche Stimme oder Tonlage) gerendert werden, um den jeweiligen Status anzuzeigen.
Um Stylesheets zu ermöglichen, einen Stil anwenden zu können, oder um anderen Mechanismen zu erlauben, Ruby-Text in sachgemäßer Form zu rendern, ist es äußerst wichtig, genug Informationen über die Funktion jeder Komponente zu bieten. Das folgende Beispiel illustriert den Gebrauch des class-Attributs, welches Stylesheets gestattet, die exakte Darstellung des Ruby-Textes zu definieren. Die (CSS-)Klasse reading wird auf einen Ruby-Text angewandt, um die Lesart zu definieren; die Klasse annotation wird gebraucht, um anzuzeigen, dass der entsprechende Ruby-Text die Erörterung (Annotation) des Basistextes beinhaltet. Das xml:lang-Attribut zeigt die Sprache des Textes an.
Wenn ein Stylesheet gebraucht wird, um horizontalen Text und das Rendern der Lesart vor sowie das Rendern der Erläuterung nach der Textbasis zu definieren, könnte das obige Markup wie folgt gerendert werden:
3.5 Hinweise zum non-visuellen Rendern
Dokumente, die Ruby-Markup verwenden, können in manchen Fällen von non-visuellen User-Agents wie Sprach-Browsern oder Braille-User-Agents gerendert werden. In solchen Fällen ist es wichtig, folgendes zu beachten:
- Je nach Benutzer und Situation können unterschiedliche Arten des Rendern erforderlich sein.
- Ruby-Text, der eine bestimmte Lesart repräsentiert, ist möglicherweise anders zu behandeln als Ruby-Text, der andere Informationen bereitstellt.
- Für sachgemäßes non-visuelles Rendern ist es wichtig, die Funktion jedes Ruby-Text-Bereiches zu verdeutlichen.
- Es gibt häufig Unterschiede zwischen der vom Ruby-Text angezeigten Lesart und der tatsächlichen Aussprache.
- Der Leser mag daran interessiert sein, Informationen über den Basistext (Ideogramme) zu erhalten.
Je nach den Wünschen des Benutzers kann die Art, wie ein Text (vor-)gelesen wird, zwischen schneller und flüchtiger bis hin zu äußerst sorgfältiger und detaillierter Lesart variieren. Dies kann zu verschiedenen Weisen führen, nach denen Ruby-Text beim non-visuellen Rendern behandelt wird, und zwar vom Überspringen des Ruby-Textes bei schneller Lesweise bis hin zu detaillierter Wiedergabe der Ruby-Struktur und der gegenwärtigen Beschaffenheit bei sorgfältiger Lesart.
Im häufig auftretenden Fall, dass Ruby-Texte die Lesart repräsentieren, kann das Rendern sowohl des Basis- als auch des Ruby-Textes zu störenden Duplikaten führen. Ein Sprachsynthesizer könnte hier in der Lage sein, den Basistext aufgrund eines großen Wortschatzes korrekt auszusprechen, und vielleicht kann er in anderen Fällen auch die entsprechende Aussprache anhand der vom Ruby-Text gelieferten Lesart wählen.
Nicht alle Ruby-Texte repräsentieren die Aussprache des jeweiligen Basistextes. Autoren sollten Ruby-Texte, die für andere Zwecke gebraucht werden, entsprechend mit dem class-Attribut kennzeichnen. Dies wird oben anhand der Anwendung von class="reading" auf den Ruby-Text (zum Hervorheben der Lesart) illustriert.
Ruby-Text, der die Lesart anzeigt, mag nicht unbedingt die richtige Aussprache produzieren, selbst wenn das verwendete Skript auf den ersten Blick phonetisch perfekt scheint. Bopomofo beispielsweise wird mit jedem Zeichen des Basistextes unabhängig assoziiert; kontextabhängige Klang- oder Tonveränderungen werden somit nicht widergespiegelt. Ähnlich ist es im Japanischen, wo durchaus Unregelmäßigkeiten in der Schreibweise vorkommen können, etwa bei は (»hiragana ha«) für das Themensuffix, welches わ (»wa«) ausgesprochen wird, oder beim Gebrauch von Vokalen, um die Dehnung hervorzuheben. In solchen Fällen wollen Autoren vielleicht für genau diesen Zweck die tatsächliche Aussprache mit besonderem Markup bereitstellen, oder sie verlassen sich auf ein auditives Rendersystem, das in der Lage ist, solche Fälle korrekt handzuhaben.
3.6 Alternativen zum rp-Element
Wenn der jeweilige Autor sich keine Gedanken um Fallback-Mechanismen für User-Agents macht, die weder etwas über Ruby-Markup wissen noch CSS-2- [CSS2] oder XSL-Stylesheets [XSL] unterstützen, werden rp-Elemente nicht benötigt.
Nichtsdestotrotz ist es möglich, den Ruby-Text als Fallback-Lösung in Klammern zu setzen, wenn sich zum Beispiel die Geräteauflösung nicht gut für das traditionelle Rendern von Ruby eignet. Bei Gebrauch von [CSS2] können die Parenthesen über die content-Eigenschaft ([CSS2], Abschnitt 12.2) und die :before- und :after-Pseudoelemente ([CSS2], Abschnitt 12.1) generiert werden, wie zum Beispiel in dem folgenden Style-Fragment:
In dem obigen Beispiel wird das rt-Element automatisch in Klammern gesetzt. Es wird dabei vorausgesetzt, dass die obigen Style-Regeln zusammen mit anderen Regeln verwendet werden, die den Ruby-Text inline positionieren. Die Erzeugung von Parenthesen ist ebenso einfach mit XSLT [XSLT] realisierbar.
Dieser Abschnitt ist normativ.
Im Zusammenhang mit dieser Spezifikation kann entsprechende Konformität von Markup, Dokumenttypen, Modulimplementierungen, Dokumenten, Generatoren und Interpretern erfordert werden. Für die meisten dieser Fälle sind zwei Level an Konformität verfügbar: Einfache Erfüllung und volle Erfüllung (Konformität). Einfache Erfüllung bedeutet, dass das konforme Objekt das minimale Inhaltsmodell des Ruby-Elements unterstützt (siehe Abschnitt 2.1), zum Beispiel einfaches Ruby-Markup. Volle Erfüllung bedeutet, dass das konforme Objekt das maximale Inhaltsmodell des Ruby-Elements unterstützt (siehe Abschnitt 2.1), und zwar durch die Unterstützung von sowohl einfachem als auch komplexem Ruby-Markup.
Markup entspricht einfachem Ruby-Markup, wenn es ein oder mehr ruby-Elemente beinhaltet und der Inhalt all dieser Elemente (inklusive ihrer Kindelemente) dem minimalen Inhaltsmodell aus Abschnitt 2.1 entspricht, das heißt, dass nur einfaches Ruby-Markup erlaubt ist. Markup entspricht vollem (komplexem) Ruby-Markup, wenn es ein oder mehr ruby-Elemente beinhaltet und der Inhalt all dieser Elemente (inklusive ihrer Kindelemente) dem maximalen Inhaltsmodell aus Abschnitt 2.1 entspricht, das heißt, es ist sowohl einfaches als auch komplexes Ruby-Markup erlaubt.
Ein Dokumenttyp ist ein zu einfachem Ruby-Markup konformer Dokumenttyp, wenn er einfaches Ruby-Markup durch das sachgemäße Einfügen des ruby-Elements innerhalb entsprechender Elemente und durch das Definieren der notwendigen Elemente und Attribute in konformer Form integriert. Ein Dokumenttyp ist ein zu vollem Ruby-Markup konformer Dokumenttyp, wenn er volles (komplexes) Ruby-Markup durch das sachgemäße Einfügen des ruby-Elements innerhalb entsprechender Elemente und durch die Definition der notwendigen Elemente und Attribute in konformer Form integriert.
Eine Modulimplementierung (zum Beispiel mit DTD- oder XML-Schema-Technologie) ist eine konforme Modulimplementierung von einfachem Ruby-Markup, wenn sie so entworfen wurde, dass sie einfaches Ruby-Markup zusammen mit anderen Modulen in oben beschriebene Dokumenttypen integriert. Eine Modulimplementierung ist eine konforme Modulimplementierung von komplexem Ruby-Markup, wenn sie so entworfen wurde, dass sie komplexes Ruby-Markup zusammen mit anderen Modulen in oben beschriebene Dokumenttypen integriert. Eine Modulimplementierung ist eine konforme Modulimplementierung von vollem Ruby-Markup, wenn sie so entworfen wurde, dass sie entweder einfaches oder volles (komplexes) Ruby-Markup zusammen mit anderen Modulen in oben beschriebene Dokumenttypen integriert (zum Beispiel durch Bereitstellen eines Umschaltmechanismus oder durch Anbieten zweier separater Modulimplementierungen).
Ein Dokument ist ein zu einfachem Ruby-Markup konformes Dokument, wenn es konformes einfaches Ruby-Markup und kein komplexes oder nicht-konformes Ruby-Markup beinhaltet. Ein Dokument ist ein zu vollem Ruby-Markup konformes Dokument, wenn es konformes volles (komplexes) Ruby-Markup und kein nicht-konformes Ruby-Markup beinhaltet.
Ein Generator ist ein Generator von konformem einfachem Ruby-Markup, wenn er konformes einfaches Ruby-Markup und kein komplexes oder nicht-konformes Ruby-Markup generiert. Ein Generator ist ein Generator von konformem vollem Ruby-Markup, wenn er konformes volles (komplexes) Ruby-Markup und kein nicht-konformes Ruby-Markup generiert.
Ein Interpreter ist ein Interpreter von konformem einfachem Ruby-Markup, wenn er nicht-konformes Ruby-Markup ablehnt, konformes einfaches Ruby-Markup akzeptiert, und, sobald er Ruby-Markup interpretiert, dies gemäß dieser Spezifikation tut. Ein Interpreter ist ein Interpreter von konformem vollem Ruby-Markup, wenn er nicht-konformes Ruby-Markup ablehnt, konformes volles (komplexes) Ruby-Markup akzeptiert, und, sobald er Ruby-Markup interpretiert, dies gemäß dieser Spezifikation tut. Interpreter sind dabei zum Beispiel serverseitige Analyse- oder Transformierungswerkzeuge und -renderer.
Details zur Konformität mit XHTML-Modularisierung sind unter Abschnitt 3 von [XHTMLMOD] zu finden.
Danksagung
Dieser Abschnitt ist informell.
Takao Suzuki (鈴木 孝雄) und Chris Wilson haben als Verfasser zu den vorherigen Entwürfen beigetragen.
Diese Spezifikation wäre nicht ohne die Hilfe der Mitglieder der W3C-I18N-Arbeitsgruppe möglich gewesen, insbesondere die von Mark Davis und Hideki Hiura (樋浦 秀樹) sowie die der Mitglieder der W3C-I18N-Interessengruppe.
Weitere Mitwirkende waren Murray Altheim, Laurie Anna Edlund, Arye Gittelma, Koji Ishii, Rick Jelliffe, Eric LeVine, Chris Lilley, Charles McCathieNevile, Shigeki Moro (師 茂樹), Chris Pratley, Nobuo Saito (斎藤 信男), Rahul Sonnad, Chris Thrasher.
Das in dieser Spezifikation definierte Markup wurde mit dem von der Arbeitsgruppe 2 (WG 2, Typesetting) des Electronic Document Processing System Standardization Investigation and Research Committee of the Japanese Standards Association entwickelten Ruby-Markup aus [JIS4052] in Einklang gebracht. Wir möchten den Mitgliedern der WG 2 für ihre Mitarbeit danken, insbesondere Shibano (芝野 耕司, Vorsitz) und Masafumi Yabe (家辺 勝文). Technisch gesehen unterscheidet sich das Ruby-Markup in [JIS4052] in zwei Punkten von dem aus dieser Spezifikation: Zum einen gibt es eine nicht zu XML kompatible Form von Markup, die auf besonderen Symbolen basiert, und zum anderen ist kein rp-Element erlaubt.
Wertvolle Kommentare wurden auch von der HTML-, der CSS-, der XSL- und der WAI-Arbeitsgruppe sowie Steven Pemberton, Trevor Hill, Susan Lesch und Frank Yung-Fong Tang eingebracht. Akira Uchida (内田 明) gab Rückmeldung aus Übersetzungssicht.
Ein früherer Vorschlag für bestimmtes Markup für Ruby, welches Attribute verwendet, wird in [DUR97] beschrieben.